
This category of material includes notes introducing R and providing some vignettes on its use that may be of interest to economists. Additional material is available in PDF form in the downloads. These scripts are provided with no support or warranty or guarantee as to their general or specific usability. Most recent articles are shown first
A Tidyverse Example for NDM Vector Processing
This section examines a simple script to process a seven series downloaded from the NDM vector search facility. The script reads the data and analyzes the contents. The data are then reordered by time and converted from the tall narrow format of the data as retrieved to a wide csv with time in columns. Percentage changes are calculated for selected series. A plot of one series is done. Selected series are also annualized using averages. This script was developed to highlight features of the Tidyverse for processing data into a useful form. Normally, all analysis should be done in R rather than export to older technologies such as Excel. However, in this case, the script was developed to show how to port data to CSVs useable by Excel. The full script with comments is included as Appendix A and a log file as Appendix B in the accompanying pdf in the R notes downloads..
The initial set of code sets the working folder or directory and loads the required package libraries for this simple project. The backslashes are duplicated because the backslash is an “escape” character that signals special processing of the subsequent character.
setwd( "D:\\OneDrive\\ndm_r_runs") library(tidyverse) library(lubridate)
The next set of code reads the data in using the readr routine read_csv.
input_file<-"vectorsSearchResultsNoSymbols.csv" input_data<-read_csv(input_file) print(colnames(input_data))
The print statement will show that the column names in the input_data data frame include "Vector", "Frequency", "Description", "Reference Period", "Unit of Measure", "Value" and "Source". In the discussion below, each column is considered a variable in the data frame.
One of the key features in modern R is the use of the pipe (%>%). This “pipes” the results from one command to the next and facilitates the linkage of commands without unnecessary results.
The next commands create a series directory by selecting unique or distinct values for the Vector and Description variables. The results are then printed.
series_directory<-select(input_data,c("Vector","Description"))%>%distinct()
print(series_directory)
One challenge with data retrieved from NDM is that the sort may not be optimal. For time series, most users want high to low. The other challenge is that the representation of the time period is not normal in that a day is not including with the month. Excel automatically converts Month Year combinations to dates including the first day of the month. The next command mutates the input data set to include two new variables, obs_date and obs_year. The date variable is created by pasting the string “1 “ to each reference period entry and then converting to system standard dates using the day-month-year function (dmy) from the lubridate package.
input_data<-mutate(input_data,obs_date=
dmy(paste0("1",
input_data$"Reference Period",sep="")),
obs_year=year(obs_date))
It should be noted that variable columns in a data frame are referenced by using the data frame name concatenated with the $ sign to the variable name. Variable names with embedded blanks must be enclosed in quotes.
The next command creates a sorted data frame by vector and date, mutates it to include the variable obs_pch which is the percentage change and filters the data to include only data from 2015 forward.
sorted_data<-arrange(input_data,Vector,obs_date)%>%
mutate(obs_pch=((Value/lag(Value,1))-1)*100)%>%filter(obs_year>=2015)
The sorted_data data frame is still a tall data frame with one value observation per row. The next command set creates a value_spread data frame with the vector number, the description and a new variable Type indicating that the data are untransformed. The data are spread into a wide data set with one column for each month in obs_date.
value_spread<-select(sorted_data,Vector, Description,
obs_date,Value)%>%mutate(Type="Raw")%>%
spread(obs_date,Value)
Note that in R, the capitalization of all variables is critical. In other words, to be found, Description must be capitalized.
We want to add percentage change data to the analysis. However, the vectors chosen for this run include 3 vectors from the Bank of Canada’s price series which are already in change format. Therefore, they should be excluded from the calculation. This is done by excluding all rows with vector names in a list defined from the 3 Bank series.
boc_series<-c("V108785713", "V108785714", "V108785715")
pch_spread<-select(sorted_data,Vector,Description,obs_date,obs_pch)%>%
mutate(Type="PCH")%>%
filter(!(Vector %in% boc_series))%>%
spread(obs_date,obs_pch)
The filter command uses the logical not (!) to exclude vectors in the list of bank series.
The final two commands concatenates the two frames by row using the rbind command and writes the resulting output data frame to a CSV file.
output_data<-rbind(value_spread,pch_spread)
write.csv(output_data,file="Vector_output_data.csv")
The first columns of the resulting data set are shown below.
Just to show that one can do some work in R, the next lines select and plot the labour force average hourly wage rate. The resulting chart is saved as PNG file. The chart title is extracted from the series directory created above.
plot_series<-"V2132579"
chart_title=select(series_directory,Vector,Description)%>%filter(Vector==plot_series)
plot_data<-select(sorted_data,Vector,obs_date,obs_pch)%>%filter(Vector==plot_series)
plot1<-ggplot(plot_data,aes(x=obs_date,y=obs_pch))+geom_line()+
labs(title=chart_title$Description,x="Date",y="Percentage Change")
ggsave(plot1,file=paste0(plot_series,"_percentage_change.png"))
The resulting graph is show below. It uses basic defaults.
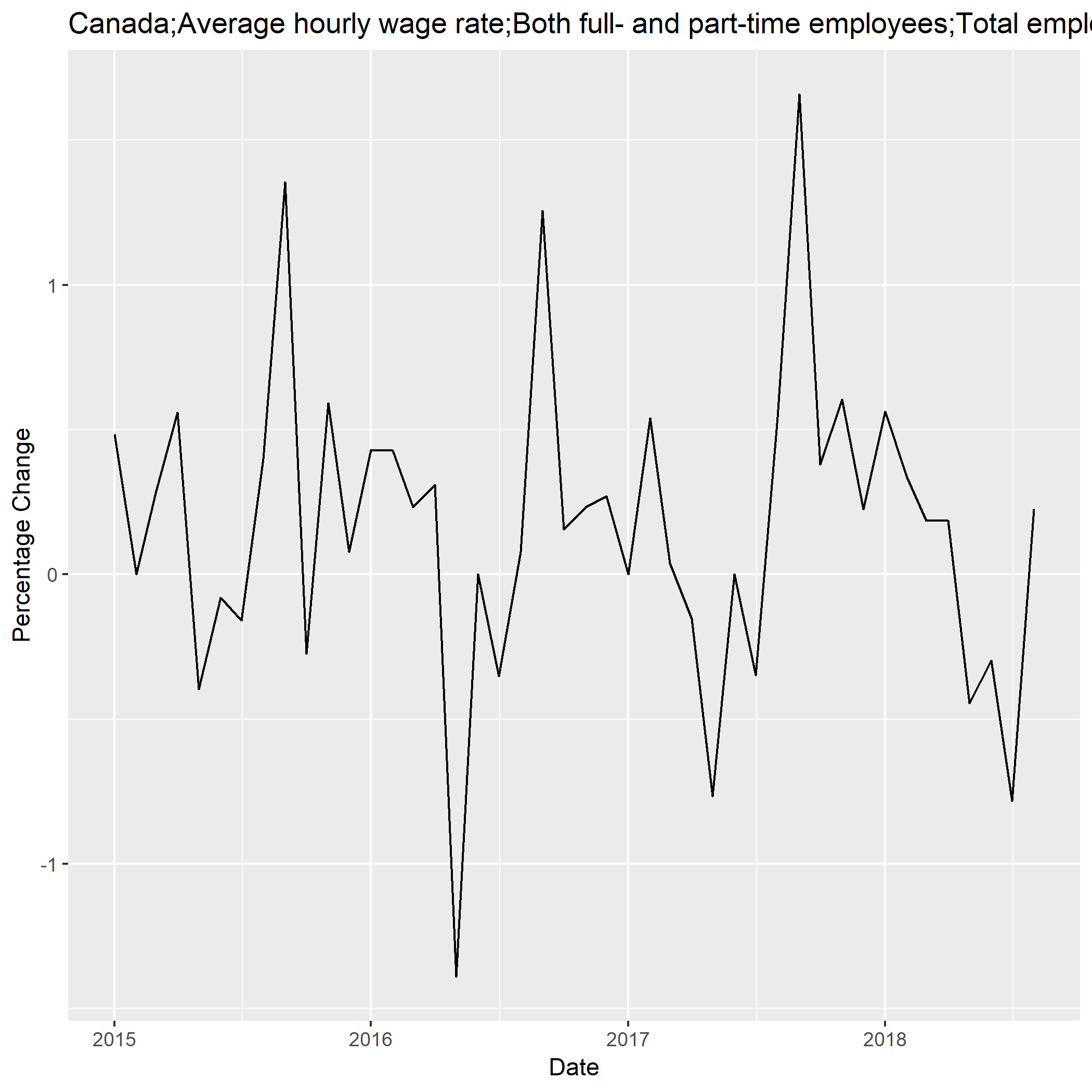
The final task in this simple script is to create an annualized data set. This means to take the annual average of all series. However, the labour force wage rate is excluding because correct annualization requires weighting by monthly employment which is not available in the data set.
lfs_series<-"V2132579"
annual_spread<-select(sorted_data,Vector,Description,obs_year,Value)%>%
filter(!Vector==lfs_series)%>%
group_by(Vector,Description,obs_year)%>%
summarize(Value=mean(Value))%>%
mutate(Type="Annual Average")%>%
spread(obs_year,Value)
write.csv(annual_spread,file="Annualized_vector_data.csv")
In this section of code, the key verb is the group_by command which sets the limits for which the mean or average calculation is applied (by year) and includes unique copies of the Vector and Description in the output data set before spreading it by year.
The resulting data set is shown below.

Introducing R
TIntroducing R to Economists
This note outlines some key documentation on the statistical programming language R to provide an introduction to new users, particularly economists. The note will also go through a specific example of using data retrieved as vectors from Statistics Canada’s New Dissemination Model (NDM). The focus of this note is on manipulating or wrangling the data rather than specific topics such as forecasting or regression.
R and How to Get it
R is an open source statistical programming language with open-source implementations available for Windows, Mac and Linux. No seat licenses are required but no warranty is provided either. Documentation is available online as are the executables. The base system is extendable by an extensive library of open-source packages which are also available on line.
The key starting point is the web site R-Project web site – https://www.r-project.org. The software is downloadable from the Comprehensive R Archive Network or CRAN for short. This library is mirrored on the computing facilities of many institutions around the world. The starting link is https://cran.r-project.org/mirrors.html but the best link is the cloud redirection system sponsored by RStudio at https://cloud.r-project.org which simply moves the request to an appropriate server.
There is also an implementation of R maintained by Microsoft at https://mran.microsoft.com which should be considered for large scale operations requiring integration into the Microsoft world.
Key General Documentation
The main documentation source is maintained by the core development team at https://cran.r-project.org/manuals.html but there are many other very strong web sites documenting specific features and packages. A detailed introduction to using R is available online and in PDF in the manual link shown above. The specific link is https://cran.r-project.org/doc/manuals/r-release/R-intro.html.
Many of the best sites are associated with books by the authors of the web sites. The list below includes some that I have found very useful.
- Quick – R – a site associated with the book “R in Action” by Robert Kabacoff. The book is strongly recommended but the web site is a great substitute. The link is https://www.statmethods.net/index.html and contains many useful examples relevant to our profession. It is an excellent starting point because it assumes no prior R knowledge.
- Cookbook for R – a site associated with the book “R Graphics Cookbook” by Winston Chang, one of the R studio team associated with the key graphics package ggplot2. The link is http://www.cookbook-r.com/ includes a basic tutorial as well.
- The book “Art of R Programming” by Norman Matloff is available from Amazon and other suppliers. It is older but still used by many. The Amazon link is https://www.amazon.ca/Art-Programming-Statistical-Software-Design/dp/1593273843 Some unlicensed copies can be found on the web.
- Hadley Wickam, one of the R gurus, is the force behind many key packages has produced a number of books.
- “R for Data Science” by Garrett Grolemund and Hadley Wickham is highly recommended for more advanced users interested in the effective workflow of data visualization and analysis projects. This is the text book for the tidyverse system mentioned below. The book is available and recommended but an open source web version is also available. All the authors ask is for donations to support an endangered parrot. The link is http://r4ds.had.co.nz/.
- “Advanced R” by Hadley Wickam covers more advanced elements of working with R. As well as a book, the material is available in a web site at http://adv-r.had.co.nz/.
- There are many books on specific technical topics incorporating the use of R. Forecasting is particularly important in our profession. Rob Hyndman and George Athanasopoulos have developed “Forecasting Principles and Practice” with a book available from Amazon and an online textbook available at https://otexts.org/fpp2/.
Packages
R incorporates many key packages of routines in the base installation. However, there are many packages specifically written for key tasks. Formal documentation, often in PDF form is available on CRAN. An excellent web site organizing the documentation is maintained at https://www.rdocumentation.org/.
This list, below, is only some basic suggestions.
Tidyverse
Tidyverse is the acronym developed by Hadley Wickem to define a suite of integrated packages for data wrangling and visualization. Data wrangling is the term for getting your data clean and organized before you start your research. Tidyverse is documented at https://www.tidyverse.org/. It emphasizes the use of an augmented data structure referred to as a tibble which is a tall organization of data. This means attributes are consolidated in a few columns and values into only one. The key packages in the base Tidyverse are:
- dplyr - the main data manipulation package incorporating a consistent grammar for data manipulation. Key verbs include:
- mutate() adds new variables that are functions of existing variables
- select() picks variables based on their names.
- filter() picks cases based on their values.
- summarise() reduces multiple values down to a single summary.
- arrange() changes the ordering of the rows.
- ggplot2 – one of the go-to packages for graphics in R
- readr – a suite of routines for reading datasets into R – notably read_csv which are much more effective than the base routines.
- tidyr – a set of routines to manipulate tall datasets such as often come from NDM into wide ones as well as to decompose or recompose columns of data in a useful way.
- broom – a package with useful tibble functions – tidy particularly is good to move data freams to tibbles.
- lubridate – not one of the main packages but very useful for manipulating dates into a standard representation.
Data.Table
Data.table is an alternative to dplyr. It has some speed and syntactic advantages for large datasets. It is often used in financial applications. An excellent training course is available at www.datacamp.com. The R documentation link is https://www.rdocumentation.org/packages/data.table/versions/1.11.4/.
XTS
Ordered series, often referred to as time series, do not have to be regular in terms of a fixed number of periods per aggregate period. Examples are daily data with and without weekend observations. The XTS package associates an order vector like time with a set of series. It is quite comprehensive and highly recommended. It extends the base time series object in R (ts) and builds on the capabilities of the zoo time series package. The R documentation link is https://www.rdocumentation.org/packages/xts/versions/0.11-1.
Forecast
This package includes the procedures discussed in the Hyndman book noted above. The focus is on univariate methods including Arima and various seasonal adjustment techniques. Because seasonality requires a time series with regular periodicity (i.e. monthly or quarterly), the ts time series object is emphasized. The R documentation link is https://www.rdocumentation.org/packages/forecast/versions/8.4.
MEMISC
Martin Elff, at the Zepplin University in Germany, maintains a suite of routines designed to easily manipulate microdata. It is an excellent substitute for the general functionality of STATA and similar packages. I have found it particularly useful with Statistics Canada’s PUMF datasets. Recent pumf releases are formatted sufficiently well that input into the MEMISC routines is relatively straight forward. Some have issues with the apostrophe character in the descriptions but that is easy to handle with modest edits of the input files. The package developed an extended data frame with the variables from the data file incorporating descriptors, code definitions and missing variable information as appropriate. A useful vignette is contained at this link https://cran.r-project.org/web/packages/memisc/vignettes/items.html.
Cheat Sheets
One of the documentation options that has come to the fore in recent years are cheat sheets. These are one- or two-page PDFs summarizing the key syntax and features of a package. Useful ones include:
- Data Wrangling (aka dplyr and other tidyverse) - https://www.rstudio.com/wp-content/uploads/2015/02/data-wrangling-cheatsheet.pdf
- Data Visualization – ggplot2 - https://github.com/rstudio/cheatsheets/blob/master/data-visualization-2.1.pdf
There are numerous variants of cheat sheets for various aspects of R work. A good search engine will help. The R Studio summary of R is provided as a cheat sheet relevant to the course on DataCamp. The link is https://www.rstudio.com/wp-content/uploads/2016/10/r-cheat-sheet-3.pdf.
Tom Short published a reference card for the standard R language constructs that is still used by many including myself. The link is https://cran.r-project.org/doc/contrib/Short-refcard.pdf.
Training
A search engine will provide many examples of training in R. Even YouTube contains useful videos. However, my strong recommendation is the commercial courses available from https://www.datacamp.com/ which includes a number of free courses such as an introduction to R. The service includes courses on time series analysis and many other data science topics. An excellent Android app (IOS is probably available) provides practice and a few training options for R and Tidyverse, Data Wrangling and Python.
One important feature of the Datacamp approach is that the actual lessons are done using an online version of R. This means that people can learn and practice on specific machines without installing the software. My personal experience is that this is very productive.
Many universities offer online courses for R. Harvard University has a version integrated tightly with Datacamp but with their own instructor. It is part of their data science program which includes a number of free online courses. The course is free but you pay for a certificate of completion. The link is https://www.edx.org/course/data-science-r-basics. This is a 4 week course requiring 2-4 hours per week but is self-paced.
The EDX site, used by Harvard, lists many courses from many universities and other organizations. For example, Harvard has a regression course that might be of interest to business economists. The link is https://www.edx.org/course/data-science-linear-regression. A more extensive course on regression analysis with R is offered by the Georgia Institute of Technology. The link is https://www.edx.org/course/statistical-modeling-and-regression-analysis.
Ideas.
One of the key requirements to develop your professional knowledge is to find help with specific tasks. Professionals often use a site called StackOverflow.com which includes an R section. Searching there for your problem may help.
The graphics features of R are extremely powerful. There are several packages including ggplot2. Ideas for useful graphs can be found at https://www.r-graph-gallery.com/ which includes not just pictures of the charts but also code. It is a little cumbersome to navigate but very useful. Here is the link to a heat map example https://www.r-graph-gallery.com/215-the-heatmap-function/
Books and associated sites such as those by Kabacoff and Chang are key sources of ideas. Chang’s book and web site have great discussions of graphs as well as introductory material for R.
Search engine use will identify other sites, but many are oriented to selling training programs.
Developing Code
R is a programming language. The user interface executes scripts from files or commands typed into the interface. Many people may just use it interactively at first. For many years, programmers just used text editors to develop the scripts. My personal preference for the usual ad-hoc projects, that I undertake, is to use a specific programmer’s editor known as Notepad++. It is available only for Windows. It offers the advantage of free open-source software. It incorporates a syntax processor for the functions in R and is very good at identifying unbalance parentheses and other issues. It is available at https://notepad-plus-plus.org/.
Many programmers prefer to use an integrated development environment (IDE). It includes a console, syntax-highlighting editor that supports direct code execution, as well as tools for plotting, history, debugging and workspace management. There is an open-source version for producing open-source products and a commercial one (for creating restricted license applications) available at https://www.rstudio.com/products/RStudio/#Desktop. It is a powerful system but imposes a particular organization on your project in terms of file organization and workflow that may be too complex or restrictive for ad hoc requirements.
R and the Future of NDM
One of the key features of NDM is the evolving webservices API which facilitates direct programmable access to the database. Several packages are starting to make use of these interfaces.
CANSIM2R
Marco Lugo’s CANSIM2R provides a very useful interface to retrieving full tables programmatically. It’s default of renaming variables to generic names may cause some difficulties in project implementation. It is available in CRAN. The R documentation link is https://www.rdocumentation.org/packages/CANSIM2R/versions/1.14.1.
Mountain Math CANSIM
The Mountain Math team are developing a most promising CANSIM package that includes the ability to directly download individual series. It is not yet available on CRAN because it is still being improved. It is currently available on GITHUB (a development site) only. When the package is available, it should be the preferred route for most R users to access NDM series.
R and Reproducible Research
Throughout much of the R material, there is a significant emphasis on the concept of reproducible research. The concept is relatively simple. Research should be delivered in form that documents the data used and all steps in the analysis. Because R can be used to author many forms of documents including Word, PDF, TeX, PowerPoint, etc., it is ideally suited to the task. Rather than use multiple programs, researchers develop scripts which download the data, do the analysis and graphics and combine them into a distribution ready report. JCI uses these tools to produce its monthly Retail Fast Facts publication for a client. All stages including the download of the data, the analysis and production of the master Word document are done in integrated R scripts.
In short, R facilitates a capital-intensive approach to analysis which facilitates easy replication. The advent of direct access to the NDM introduces an issue. Data retrieved from Statistics Canada should always be saved with the analysis to preserve the vintage of the information.